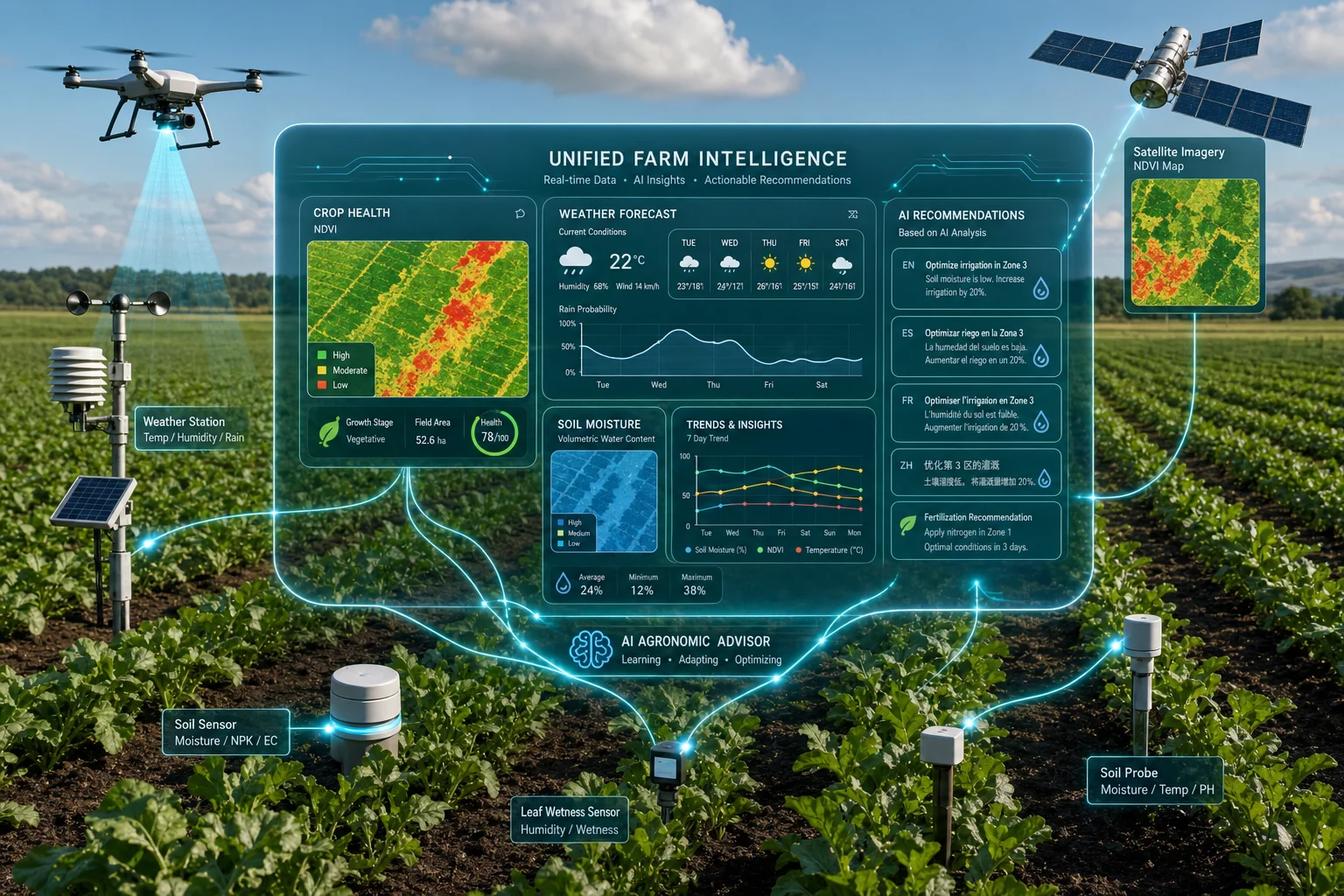
ИИ для прогнозирования урожайности пшеницы звучит как что-то сложное и «только для больших компаний». На практике это рабочий инструмент, который можно внедрять постепенно, без резких движений и без «магии». Главное — идти по шагам и заранее понимать, какие решения вы хотите улучшить.
Если говорить совсем просто, задача ИИ здесь такая: на основе данных прошлых сезонов и текущей обстановки оценить, какой урожай вы с большой вероятностью получите по конкретному полю или участку поля. Не в духе «будет хороший год», а в более прикладном формате: где, скорее всего, недобор, где норма, где зона риска, где нужно быстрее принимать меры.
Это руководство сделано для непрофессионалов в data science: фермеров, управляющих, агрономов, руководителей производства. Без лишней терминологии, но с достаточной глубиной, чтобы реально запустить пилот и понять, окупается ли он в вашем хозяйстве.
Что ИИ-прогноз даёт хозяйству на практике
Когда прогноз урожайности работает, он помогает не «красиво смотреться в презентации», а снижать неопределённость в конкретных процессах:
- планирование закупок (удобрения, СЗР, ГСМ) — меньше перезакупа «на всякий случай»;
- логистика уборки — лучше распределение техники и смен;
- загрузка хранения — меньше сюрпризов по элеватору/складу;
- финансовое планирование — более реалистичный сценарий выручки;
- управление рисками — раннее выявление проблемных зон.
Ключевой принцип: прогноз не заменяет агронома, а даёт ему более точную «карту решений». Окончательное решение всегда остаётся за людьми в поле.
Кому это подходит, а кому пока рано
Подходит, если у вас:
- есть хотя бы 2–3 сезона данных по урожайности (пусть даже не идеально чистых);
- поля более-менее описаны (контуры, площади, история операций);
- вы готовы запускать пилот на ограниченной площади (например, 100–300 га).
Пока рано, если:
- данные полностью разрознены и их нельзя связать с полями;
- нет человека, который отвечает за сбор и качество данных;
- нет понимания, какие именно управленческие решения вы хотите улучшить.
Но даже в этом случае можно начать с подготовительного этапа: привести учёт в порядок, стандартизировать записи по полям и операциям, собрать единый архив за прошлые сезоны.
Объясняем базовые термины «по-человечески»
Ниже — коротко о том, что чаще всего пугает в теме ИИ:
- Признаки (features) — это параметры, по которым модель учится: осадки, температура, NDVI, даты посева, сорт и т.д.
- Модель — алгоритм, который ищет закономерности между признаками и итоговой урожайностью.
- NDVI — индекс вегетации по спутнику: косвенно показывает, насколько активно развивается растительность.
- MAE — средняя абсолютная ошибка прогноза (в понятных единицах урожайности).
- MAPE — средняя ошибка в процентах.
- Переобучение — когда модель «выучила прошлое» слишком хорошо, но плохо работает на новых данных.
Если совсем кратко: хорошая модель — это не та, у которой «красивые графики», а та, которая стабильно помогает принимать более правильные решения в новом сезоне.
Какие данные нужны в минимально рабочем варианте
Чтобы начать, не требуется супердорогая инфраструктура. Для первого пилота часто хватает:
- истории урожайности по полям/участкам за 2–3 года;
- метеоданных по дням (осадки, температура, экстремумы);
- спутниковых данных (NDVI и близкие индексы по фазам развития культуры);
- базовой агрономической информации (дата посева, сорт, ключевые операции).
Дополнительно, если есть:
- карты почв и агрохимии;
- данные датчиков влажности;
- снимки БПЛА;
- данные по фактическим нормам внесения и дифференцированным операциям.
Это повышает точность, но не является обязательным условием старта.
Самая важная часть — подготовка данных
На практике 60–80% времени проекта уходит не на «нейросеть», а на порядок в данных. Это нормально. Если база криво собрана, даже продвинутая модель будет ошибаться.
Что нужно сделать обязательно
- Привести поля к единому справочнику: одинаковые названия, корректные контуры, актуальные границы.
- Проверить геопривязку: чтобы урожайные карты, спутниковые слои и погодные данные «смотрели» на один и тот же участок.
- Убрать явные выбросы и пропуски: например, нулевая урожайность там, где уборка точно была.
- Собрать признаки по фазам развития пшеницы, а не одной усреднённой цифрой за сезон.
Частая ошибка новичков
Начинают с вопроса «какой алгоритм лучше?», хотя правильный первый вопрос — «насколько чистые и сопоставимые у нас данные?». Если качество входов низкое, спор LightGBM vs нейросеть почти не имеет смысла.
Какую модель выбрать первой: простой и надёжный путь
Если вы делаете первый проект, стартуйте с табличной модели:
- LightGBM / XGBoost — быстрый запуск, понятные результаты, хорошая база для сравнения.
Следующие шаги (по мере зрелости данных):
- CNN — если хотите глубже использовать пространственную структуру спутниковых изображений;
- LSTM/Transformer — если у вас длинные и качественные временные ряды;
- ансамбль моделей — если нужно повысить устойчивость прогноза.
Важно: «сложнее» не всегда значит «лучше». Во многих хозяйственных задачах аккуратно настроенный LightGBM даёт очень достойный результат и быстро выводит проект в практику.
Как проверять качество прогноза правильно
Проверка — это не формальность. От неё зависит, будете ли вы доверять модели в реальном сезоне.
На какие метрики смотреть
- MAE — удобно понимать в привычных единицах (например, ц/га);
- MAPE — хорошо показывает процент ошибки;
- $R^2$ — дополнительная метрика общей объясняющей способности.
Почему этого мало
Нужно смотреть не только среднюю ошибку, но и структуру ошибок:
- на каких полях модель промахивается чаще;
- в какие годы точность заметно падает;
- есть ли «слепые зоны» (например, после погодных аномалий).
И ещё одно правило: делайте проверку по времени (train на старых сезонах, test на более новых), чтобы модель не «подглядывала в будущее».
Пилот на 100–300 га: пошаговый сценарий
- Определите цель пилота. Например: снизить перезакуп удобрений и повысить точность планирования логистики уборки.
- Выберите контур пилота. 100–300 га, где есть неоднородность и доступна история данных.
- Соберите датасет за 2–3 сезона. Убедитесь, что данные согласованы по полям и датам.
- Подготовьте baseline-модель. LightGBM + понятный набор признаков.
- Оцените качество. MAE/MAPE + разбор ошибок по участкам.
- Встройте прогноз в один процесс. Например, в планирование закупок/логистики.
- Зафиксируйте KPI пилота. И только после этого принимайте решение о масштабировании.
Если на шаге 5 точность пока средняя — это не провал. Часто уже на первой итерации видно, какие данные нужно улучшить, чтобы модель заметно выросла по качеству во второй версии.
Экономика проекта: как считать без самообмана
Один из главных рисков — считать «идеальную» окупаемость на красивых предположениях. Лучше считать консервативно.
Что включить в затраты
- подготовка и очистка данных;
- разработка/настройка модели;
- интеграция в ваши рабочие процессы;
- поддержка и обновление модели в сезоне.
Что включить в эффект
- снижение избыточных закупок;
- уменьшение потерь от ошибок логистики уборки/хранения;
- более точное планирование финансовых потоков.
Расчётный пример (понятный и честный)
Допустим, хозяйство 3 000 га, из них пилот — 300 га. Если проект даёт даже умеренный эффект: 3–5% на управляемых статьях затрат + снижение операционных ошибок в сезон, то пилот уже может окупаться в разумный срок. Но итоговый расчёт всегда индивидуален: под ваши цены, структуру затрат и организацию работ.
Правильный подход: считать три сценария — пессимистичный, базовый, оптимистичный. И принимать решение по базовому, а не по самому красивому.
Типичные ошибки при внедрении (и как их избежать)
- Ошибка 1: ждать идеальных данных. Лучше запустить первый пилот и улучшать данные итеративно.
- Ошибка 2: пытаться сразу «всё автоматизировать». Начните с одного процесса и понятных KPI.
- Ошибка 3: доверять только одной метрике. Смотрите на ошибки по полям и сезонам.
- Ошибка 4: нет владельца проекта. Должен быть ответственный, кто ведёт проект от данных до решений.
- Ошибка 5: модель не обновляется. После каждого сезона делайте переоценку и ретренинг.
Кто должен быть в команде пилота
Для старта не нужна большая команда. Обычно достаточно:
- агроном/производственник — даёт контекст по полям и операциям;
- ответственный за данные — собирает и приводит данные к единому виду;
- аналитик/подрядчик по модели — строит и тестирует прогноз;
- руководитель проекта — следит за сроками, KPI и применением результата.
Если одного из этих элементов нет, проект чаще всего «застревает» между технической частью и реальной практикой.
План на 90 дней: от идеи до управленческого эффекта
Первые 30 дней
- собрать данные за прошлые сезоны;
- стандартизировать поля и справочники;
- подготовить первую версию признаков.
31–60 день
- обучить baseline-модель;
- проверить качество по времени и по полям;
- определить зоны, где прогноз полезен уже сейчас.
61–90 день
- встроить прогноз в 1–2 управленческих процесса;
- собрать KPI пилота в живой работе;
- принять решение: масштабировать, доработать или сменить контур задачи.
Частые вопросы (FAQ)
Нужен ли штатный data scientist?
Для первого пилота — не обязательно. Можно начать с внешнего подрядчика или небольшой проектной команды. Но внутри хозяйства всё равно нужен ответственный за данные и применение результата.
Сколько сезонов данных минимум?
Обычно 2–3 сезона — минимально приемлемый старт. Один сезон почти всегда недостаточен для стабильной модели.
Можно ли запускать без датчиков в поле?
Да. Спутники + метео + история урожайности уже дают рабочий фундамент. Датчики обычно повышают точность, но не являются обязательным условием старта.
Что важнее: точность прогноза или интеграция в процессы?
Нужен баланс. Но в реальности даже неплохой прогноз бесполезен, если на его основе никто не меняет операционные решения.
Итог простыми словами
ИИ-прогноз урожайности пшеницы — это не про «модную технологию», а про управляемость хозяйства. Начинайте с небольшого пилота, считайте эффект честно, улучшайте данные поэтапно и привязывайте прогноз к реальным решениям. Такой подход работает лучше, чем попытка сразу построить идеальную систему.
Для углубления темы посмотрите раздел Фермозавра по ИИ в сельском хозяйстве, материалы по точному земледелию, практический калькулятор урожайности, а также агрометео-инструменты и котировки для увязки прогноза с рынком.